High Energy Statistics
Before I begin apparently this word has become a piece of high energy physics jargon. However its usage has become so ingrained in everything I do. High statistics = lots of events, low statistics = not many data points. It has got to the point where I am not even sure that this is not common usage of the term. But there it is.

Several months ago I listened to a RI discussion on some issue in botany as a podcast whilst out running. A member of the audience asked an uneducated question to which I found myself rattling off a standard particle physics response. The subject matter was of a statistical nature. In science \(X\) rarely happens because of \(Y\), instead we have evidence for \(X\) in some sample \(Y\). It prompted a long think of the similarities between particle physics and botany.
The First Modern Statistician.

After a brief stint teaching, Ronald Aylmer Fisher turned down Karl Pearson, the worlds foremost expert on statistical theory, and a position at University College London, to instead move to work for at the Rothamsted Experimental Station. Here he could look at a wealth of agricultural data that had been accumulated over 80 years. It was during his time here that he developed what became the foundations of modern statistical theory, in the invention of the analysis of variance (ANOVA), error functions of statistics and popularised modern usage of Maximum Likelihood Methods and p-values.
But why plants?
Randomness, is a part of nature. Randomness is just as crucial to evolutionary biology as sunlight or nutrients. Thus on trying to analyse why crops behaved this way or that, Fisher had to master randomness itself in order to arrive at the truth.
The wealth of data at Rothamsted allowed Fisher to forever change the way we assess the outcome of experiments. When randomness is involved high statistics is the only way to extract the truth
Scaling up to Particles
Particle physics has randomness built in. Randomness that Einstein famously rejected saying ‘God does not play dice!’ quantum weirdness is weird because probability plays a leading roll in in describing how particles live and die. Each of the primary experiments at the LHC produces more data the entire 80 year Rothamstead archive every single second. As such every analyst is trained to see the quantity of data received as statistics. The Higgs boson isn’t a lump of rock that we poke with sticks and write down how it wiggles. The plots and distributions are literally manifestations of how the Higgs looks and behaves.
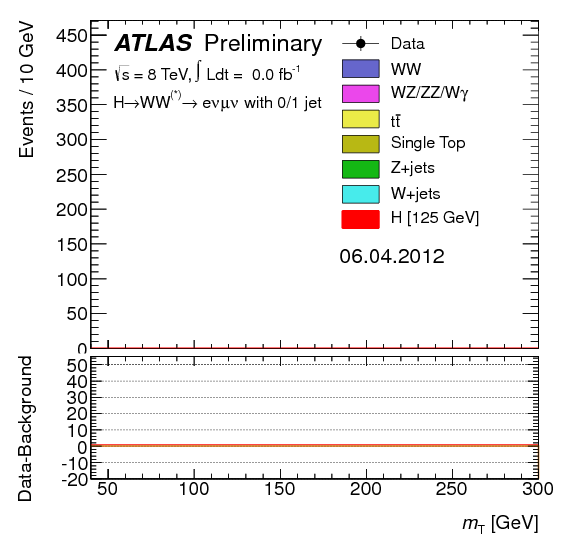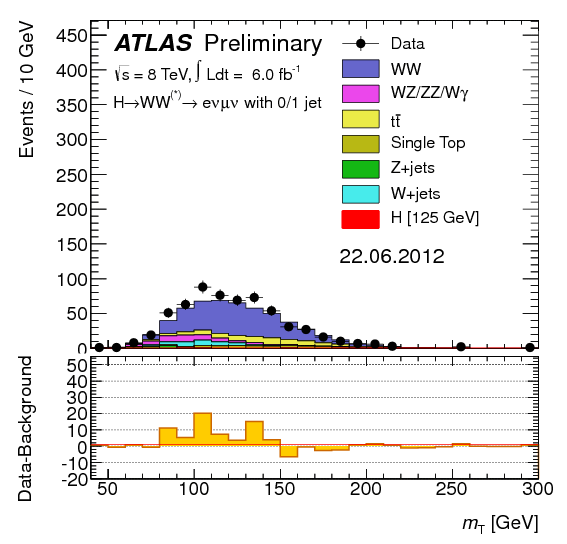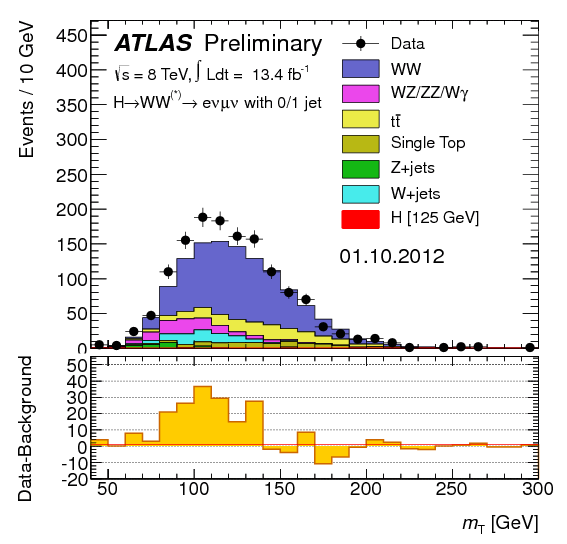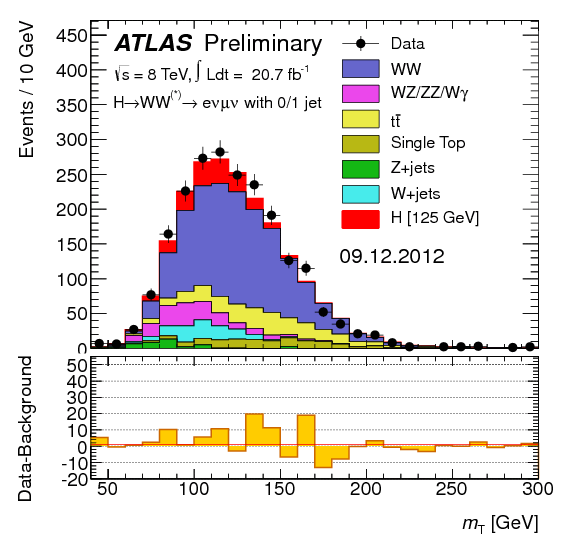
Bigger Stats = Bigger Data
Hence the need for the world wide web and now the grid. Why physics departments around the world are investing billions into high energy physics oriented data centres. Just like the randomness in biology that sparked a revolution in evolutionary genetics, quantum weirdness in particle physics is pushing for faster analyses, of denser information, of quantities of data never before seen on experimental scales. Our models can involve hundreds or even tens of thousands of parameters, and the billions of measurements split over several measurements and statistics is at the heart of it all.
